Building Real-Time Analytics with Apache Kafka
Discover how to implement streaming analytics pipelines using Kafka for instant business insights.
Introduction to Real-Time Analytics
Real-time analytics represents a paradigm shift in how organizations process, analyze, and act upon their data, enabling instant responses to business events, customer behaviors, and market changes as they occur in the moment. Apache Kafka stands as the cornerstone distributed streaming platform that powers countless modern analytics solutions across industries, serving as the technological backbone for industry giants like Netflix, Uber, LinkedIn, and Airbnb to process millions of events per second with remarkable reliability and scalability. In today's hyper-competitive business landscape, the ability to make data-driven decisions in real-time can literally mean the difference between capturing a fleeting business opportunity and losing it to more agile competitors who can react faster to changing market conditions and customer needs.
Traditional batch processing systems, while still valuable for certain analytical workloads and historical reporting, simply cannot keep pace with the demanding requirements of modern applications that need immediate insights and instant responses to rapidly changing conditions. The modern enterprise operates in an environment where customer expectations are higher than ever, market conditions change rapidly, and competitive advantages can be gained or lost in minutes rather than days or weeks. Kafka's sophisticated publish-subscribe messaging system, combined with its robust distributed architecture and fault-tolerant design, provides the scalability, reliability, and performance needed for mission-critical real-time data processing that can handle massive scale while maintaining consistency and durability guarantees.
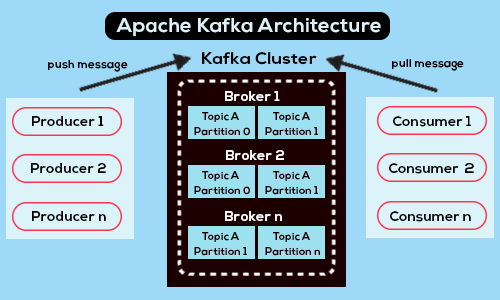
Kafka Architecture Deep Dive and Technical Foundation
Understanding Kafka's sophisticated architecture is crucial for implementing effective real-time analytics solutions that can scale to meet enterprise demands. Kafka consists of four primary components that work in perfect harmony: producers that generate and send data to the system, consumers that read and process streams in real-time or near real-time fashion, brokers that store and manage data across distributed clusters with high availability, and topics that serve as logical containers for organizing different types of messages and data streams. This architectural design enables horizontal scaling, fault tolerance, and the ability to handle massive data volumes while maintaining strict ordering guarantees and exactly-once processing semantics that are essential for financial and mission-critical applications.
Partitioning and replication strategies form the core of Kafka's scalability and fault tolerance capabilities, allowing the system to handle massive data volumes while maintaining high availability even when individual nodes fail unexpectedly. Topics are intelligently divided into partitions, which are strategically distributed across multiple brokers to enable parallel processing and horizontal scaling that can grow with your data needs. Each partition maintains an ordered, immutable sequence of records that are continually appended to a structured commit log, providing strong consistency guarantees and enabling efficient replay capabilities for disaster recovery and data reprocessing scenarios.
The replication factor, a critical configuration parameter, determines how many copies of each partition are maintained across the cluster, ensuring data durability and system resilience against hardware failures, network issues, and other infrastructure problems that could otherwise result in data loss or service disruption. This sophisticated replication mechanism, combined with Kafka's leader-follower architecture, provides automatic failover capabilities that ensure business continuity even in the face of significant infrastructure challenges.
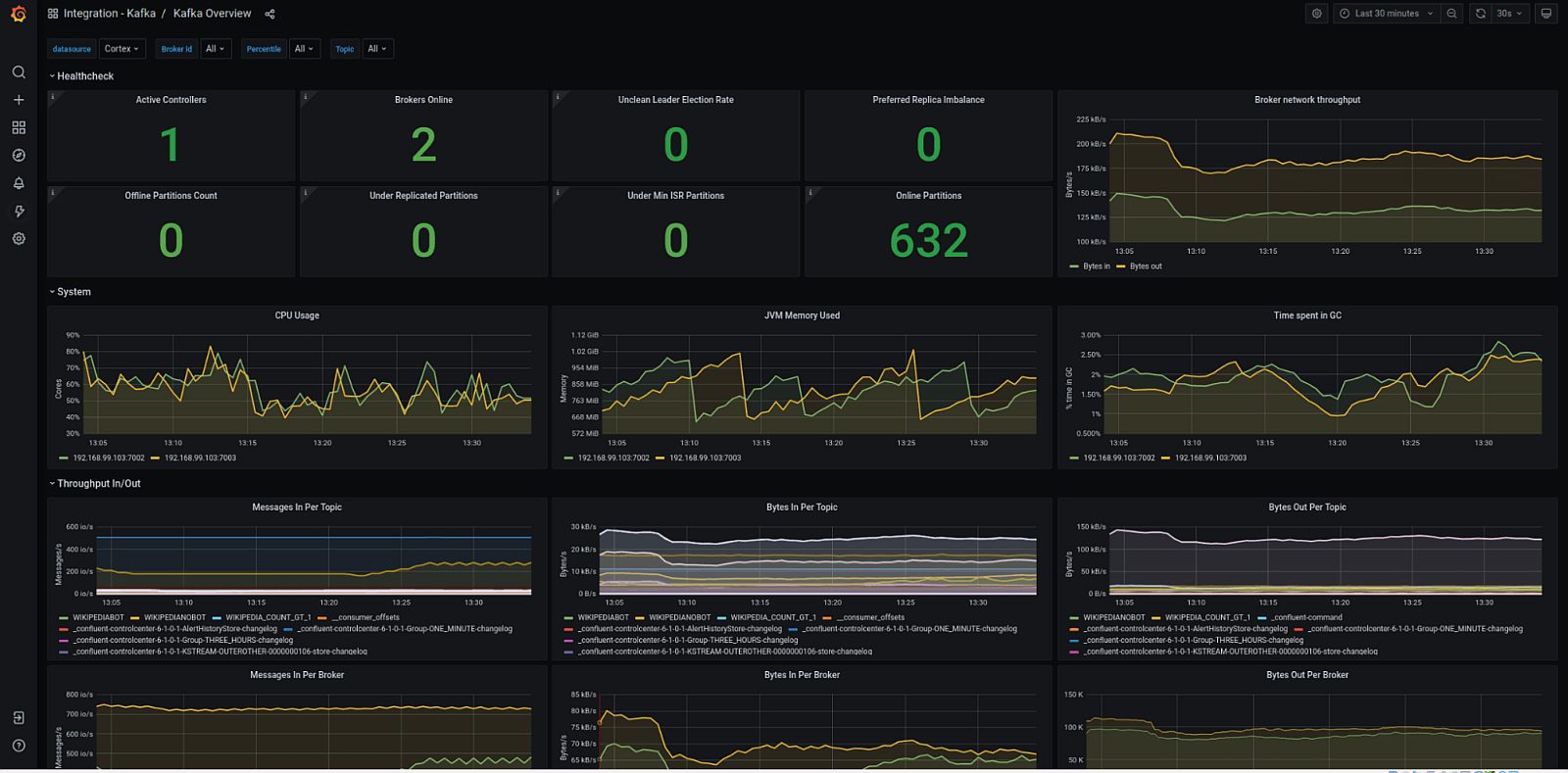
Production-Ready Kafka Cluster Implementation
Deploying a production-ready Kafka cluster that can handle enterprise-scale workloads requires meticulous planning and careful configuration of numerous parameters including replication factors, partition counts, retention policies, and resource allocation strategies to achieve the optimal balance between performance, durability, cost efficiency, and resource utilization. The complexity of these decisions increases significantly when considering factors such as expected data volume growth, message size variations, consumer lag requirements, disaster recovery needs, compliance requirements, and the need to maintain consistent performance under varying load conditions throughout different business cycles.
Comprehensive monitoring and observability represent critical components of any production Kafka deployment, requiring sophisticated tools like Prometheus for metrics collection, Grafana for visualization and alerting, and custom dashboards that track performance metrics, identify bottlenecks before they impact users, and ensure optimal cluster health across all components. Consider implementing advanced monitoring strategies that track not just basic metrics like throughput and latency, but also business-relevant metrics such as message processing delays, consumer group lag, partition distribution efficiency, and resource utilization patterns that can inform capacity planning and performance optimization decisions.
Proper sizing of brokers, configuring appropriate heap memory settings for optimal garbage collection performance, optimizing disk I/O performance through careful storage selection and configuration, and fine-tuning network settings are all critical factors for maintaining consistent throughput under varying load conditions. Network configuration, comprehensive security settings including authentication and authorization, and robust access control policies must also be carefully planned and implemented to ensure both optimal performance and strict compliance with organizational security requirements and industry regulations.
Advanced Stream Processing with Kafka Streams
Kafka Streams represents a powerful and flexible client library specifically designed for building sophisticated applications that process data in real-time, offering comprehensive support for both stateless transformations and complex stateful operations that enable advanced analytics scenarios previously requiring separate stream processing frameworks. This library provides developers with the tools needed to implement stateless transformations like filtering, mapping, and basic data enrichment operations to clean and transform individual records as they flow through your data pipeline, enabling real-time data quality improvements and format standardization that are essential for downstream analytics and reporting systems.
For more advanced use cases that require maintaining state across multiple events and time windows, Kafka Streams provides robust support for stateful operations including sophisticated windowing capabilities, complex joins across multiple data streams, and advanced aggregations that can detect patterns, calculate running totals, and correlate events across different time periods and data sources. These capabilities enable the creation of sophisticated analytics applications that can identify trends, detect anomalies, calculate key performance indicators in real-time, and trigger automated responses to specific business conditions or threshold violations.
The Kafka Streams library handles the inherent complexity of distributed processing, fault tolerance mechanisms, and exactly-once processing semantics automatically, allowing developers to focus primarily on implementing business logic rather than dealing with infrastructure concerns like state management, fault recovery, and distributed coordination. Kafka Streams applications can be deployed as lightweight microservices, making them highly scalable, maintainable, and well-suited for modern containerized environments using Docker and Kubernetes orchestration platforms.
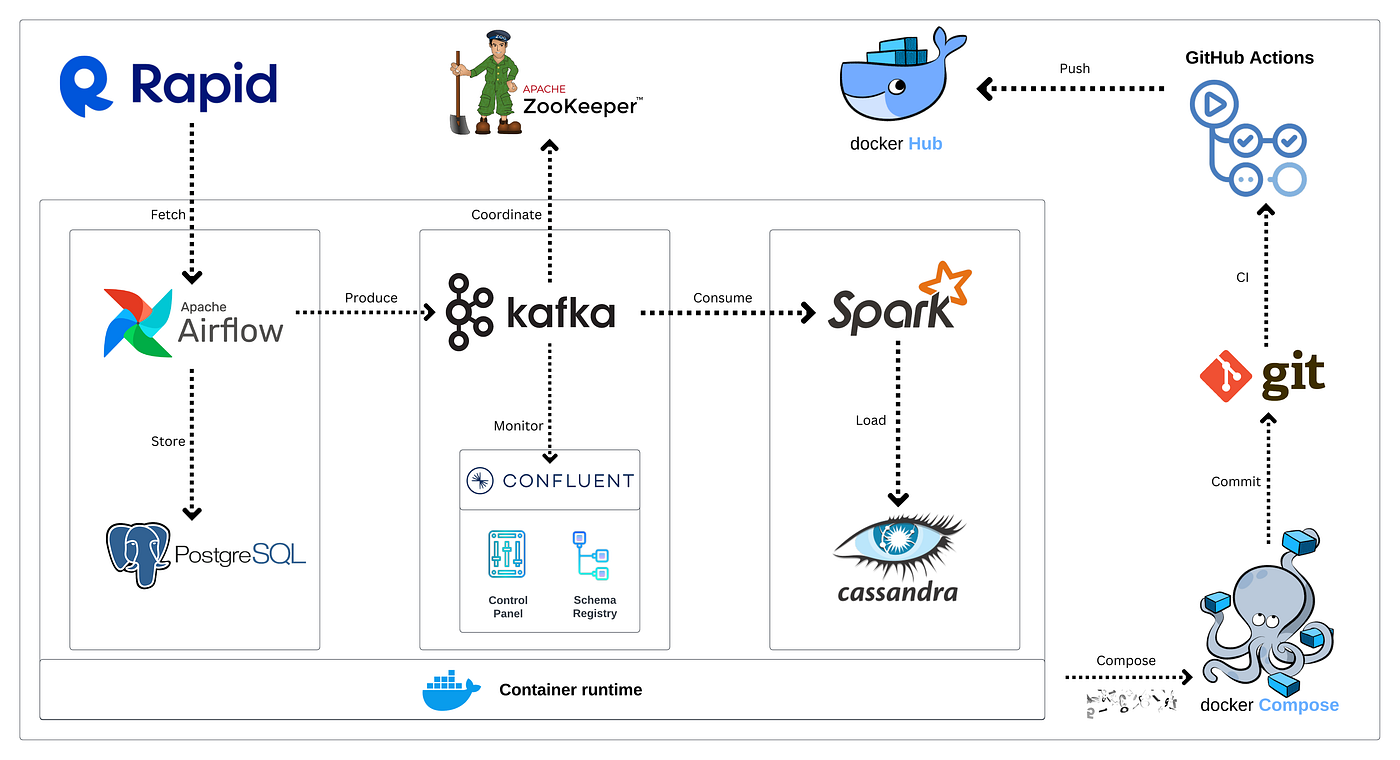
Enterprise Dashboard Integration and Visualization Strategies
Successfully connecting Kafka streams to enterprise business intelligence tools and custom dashboard solutions requires careful planning and implementation to deliver instant insights that drive immediate, informed business actions across all organizational levels. Modern integration approaches leverage Kafka Connect for seamless, code-free integration with external systems, databases, data warehouses, and third-party applications, eliminating the need for custom integration code that can be complex to maintain and scale as business requirements evolve over time and system complexity increases.
Contemporary visualization platforms and business intelligence tools can consume Kafka streams directly through native connectors or REST APIs, enabling the creation of real-time dashboards that update automatically and instantly as new data arrives, providing stakeholders with up-to-the-second insights into business performance, operational metrics, and customer behavior patterns. This real-time capability transforms traditional static reporting into dynamic, interactive experiences that enable proactive decision-making rather than reactive responses to already-occurred events.
Consider implementing differentiated visualization strategies tailored to specific audiences and use cases: executive dashboards might focus on high-level key performance indicators, strategic trends, and exception-based alerts that highlight areas requiring leadership attention, while operational dashboards should provide detailed metrics, real-time alerts, system health indicators, and actionable insights that enable immediate operational responses. The fundamental principle is ensuring that the right information reaches the right people at precisely the right time, enabling rapid, informed decision-making based on current, accurate data rather than outdated batch reports that may no longer reflect current business conditions.
Scalability, Performance Optimization, and Operational Excellence
Achieving and maintaining optimal Kafka performance at enterprise scale requires implementing comprehensive scalability strategies that include horizontal scaling through strategic addition of brokers and partitions to accommodate growing data volumes and increasing consumer demands without compromising processing speed or system reliability. This scaling approach must be carefully planned and executed to avoid common pitfalls such as partition rebalancing overhead, consumer group coordination issues, and resource contention that can temporarily impact performance during scaling operations.
Regularly rebalancing consumer groups and implementing sophisticated monitoring of consumer lag metrics are essential practices for ensuring timely processing and preventing data bottlenecks that could cascade through your entire data pipeline, potentially impacting business operations and customer experiences. Implementing comprehensive monitoring and alerting systems that track key performance indicators including throughput, latency, error rates, resource utilization, and business-specific metrics provides the visibility needed to maintain optimal performance and quickly identify and resolve issues before they impact users or business processes.
Proactive capacity planning based on monitoring trends in data volume growth, consumer processing capabilities, and resource utilization patterns enables organizations to scale infrastructure preemptively rather than reactively, ensuring consistent performance even during peak usage periods or unexpected traffic spikes. Regular maintenance tasks including log compaction, topic cleanup, performance tuning based on changing usage patterns, and infrastructure updates should be systematically planned and executed to maintain optimal system performance and reliability over time.
Strategic Conclusion and Future-Ready Architecture
Apache Kafka provides an exceptionally robust, battle-tested foundation for real-time analytics that can fundamentally transform how organizations operate, compete, and respond to opportunities in today's increasingly fast-paced, data-driven business environment. With properly designed architecture, comprehensive monitoring systems, and efficient stream processing capabilities, organizations can deliver actionable insights at massive scale while maintaining the reliability, consistency, and performance characteristics required for mission-critical applications that directly impact revenue, customer satisfaction, and competitive positioning.
The strategic investment in comprehensive real-time analytics infrastructure powered by Kafka pays substantial dividends through dramatically improved customer experiences, accelerated time-to-market for new products and services, enhanced operational efficiency, and the agility to respond quickly and effectively to market changes, competitive threats, and emerging opportunities. As data volumes continue growing exponentially and business requirements become increasingly demanding and sophisticated, Kafka's distributed, scalable architecture ensures that your analytics platform can evolve, adapt, and scale to meet future challenges while maintaining the performance and reliability that business operations depend upon for continued success and growth in an increasingly competitive marketplace.